Step 0 / 准备项目
00
建立您的虚幻工程
首先,确保您已经安装了支持的虚幻引擎版本,并将 LiteRT-LM 插件放入您的工程目录中。
Chapter 02 / 快速开始引导
建立您的虚幻工程
首先,确保您已经安装了支持的虚幻引擎版本,并将 LiteRT-LM 插件放入您的工程目录中。
从 FAB 或 Marketplace 部署
在 Fab 页面获取插件后,您可以直接在编辑器中启用它。这是开启本地大模型推理的第一步。
获取 AI 的核心大脑
访问 Hugging Face 下载指定的轻量化模型文件:
获取 gemma-4-E2B-it-litert-lm物理放置路径规范 (项目路径)
下载后,请确保文件名为 gemma-4-E2B-it-litert-lm 并放置在项目根目录的 Content 文件夹下:
[您的项目目录]/Content/Models/gemma-4-E2B-it-litert-lm
重要:请放置在项目路径而非插件路径下,以便于打包分发。同时确保项目路径中不包含中文字符,否则物理映射 (mmap) 将会失效。
下载 LiteRTDemo 仓库
为了保证插件拥有最好的性能与最精简的用法,我们不再在插件包内捆绑庞大的资源,而是免费提供了一个专门的 Demo 项目作为实战参考:
访问 GitHub 仓库克隆该项目后,将 LiteRT-LM 插件 放入 Demo 项目的 Plugins 文件夹下。打开 Demo.umap 关卡,即可直接看到完整的交互界面。
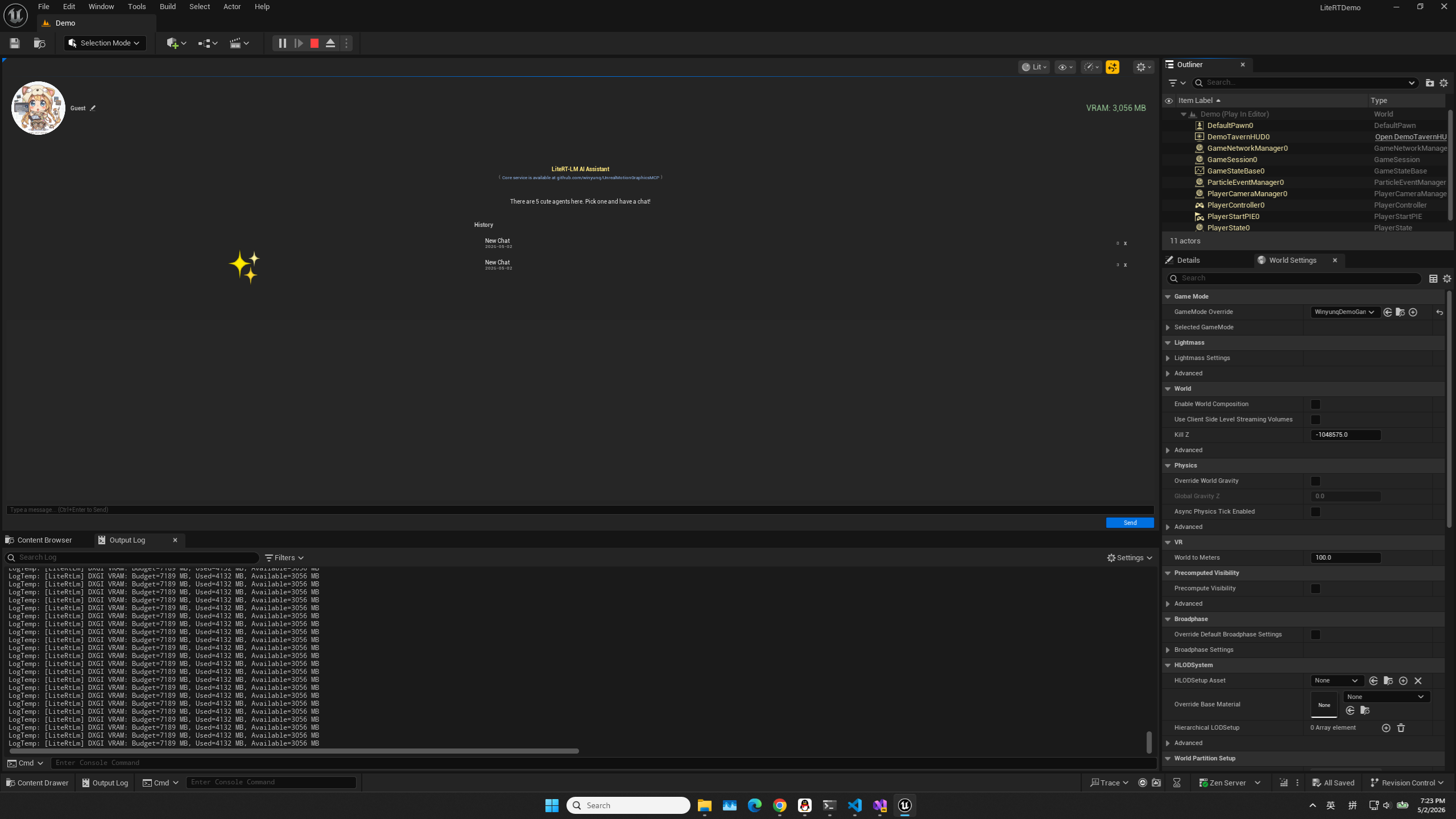
实时文本交互
在对话框中输入文字并按下回车。此时插件会根据您的 SessionKey 自动映射到显存中的 KV Cache。
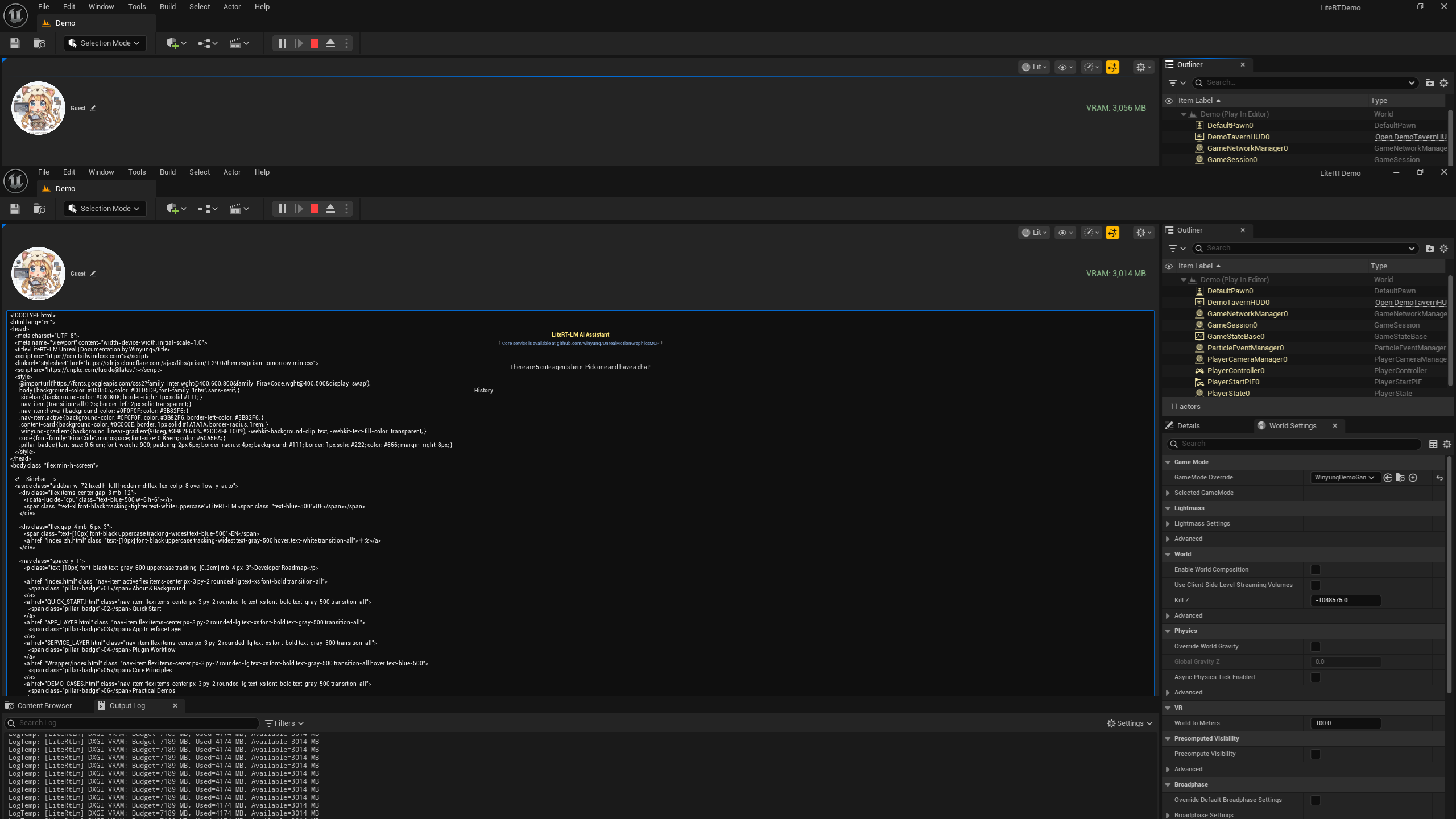
流式回复与记忆
AI 会开始逐字返回结果。借助于我们的多会话管理,NPC 会记住您的对话上下文,实现真正的智能交互。
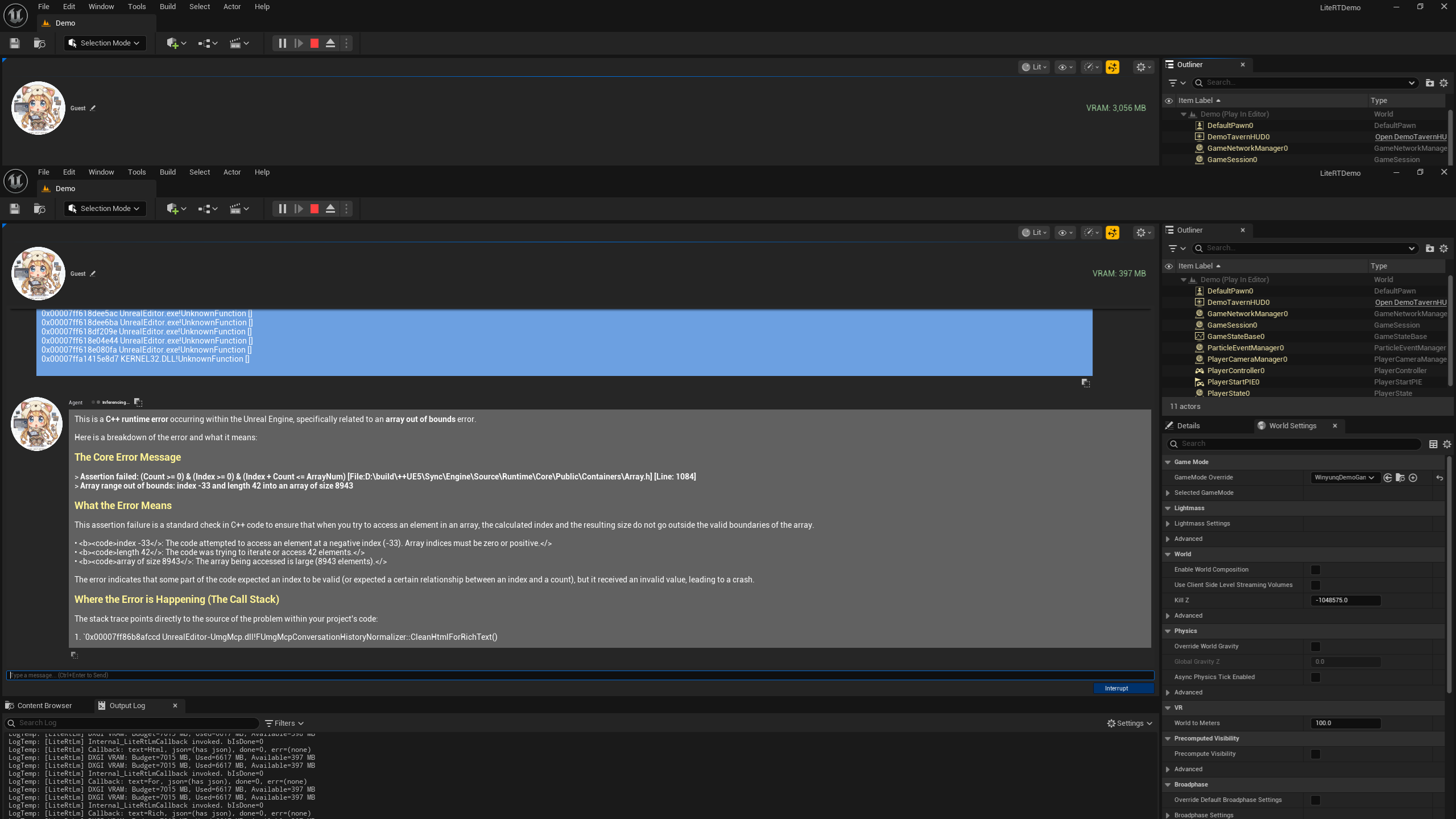
如果您已经成功运行了 Demo,现在是时候学习如何通过 C++ 驱动这一切了。
Click me to Learning Coding