Step 0 / Prepare Project
00
Setup Your Unreal Project
First, ensure you have a supported Unreal Engine version installed and place the LiteRT-LM plugin into your project directory.
Chapter 02 / Quick Start Guide
Setup Your Unreal Project
First, ensure you have a supported Unreal Engine version installed and place the LiteRT-LM plugin into your project directory.
Deploy from FAB or Marketplace
After acquiring the plugin from the Fab page, you can enable it directly in the editor. This is the first step to unlocking local LLM inference.
Acquire the Core Brain of AI
Visit Hugging Face to download the specified lightweight model file:
Get gemma-4-E2B-it-litert-lmPlacement Specification (Project Path)
After downloading, ensure the file is named gemma-4-E2B-it-litert-lm and place it in the Content folder of your Project Root:
[Your Project Dir]/Content/Models/gemma-4-E2B-it-litert-lm
IMPORTANT: Place the model in the Project Path, not the plugin path, for easier packaging. Ensure the project path contains no non-ASCII characters to avoid mmap failures.
Download LiteRTDemo Repository
To ensure the best performance and the leanest plugin package, we no longer bundle large assets within the plugin. Instead, we provide a dedicated Demo project as a production reference:
Visit GitHub RepositoryAfter cloning, place the LiteRT-LM Plugin into the Plugins folder of the Demo project. Open the Demo.umap level to see the complete interactive interface.
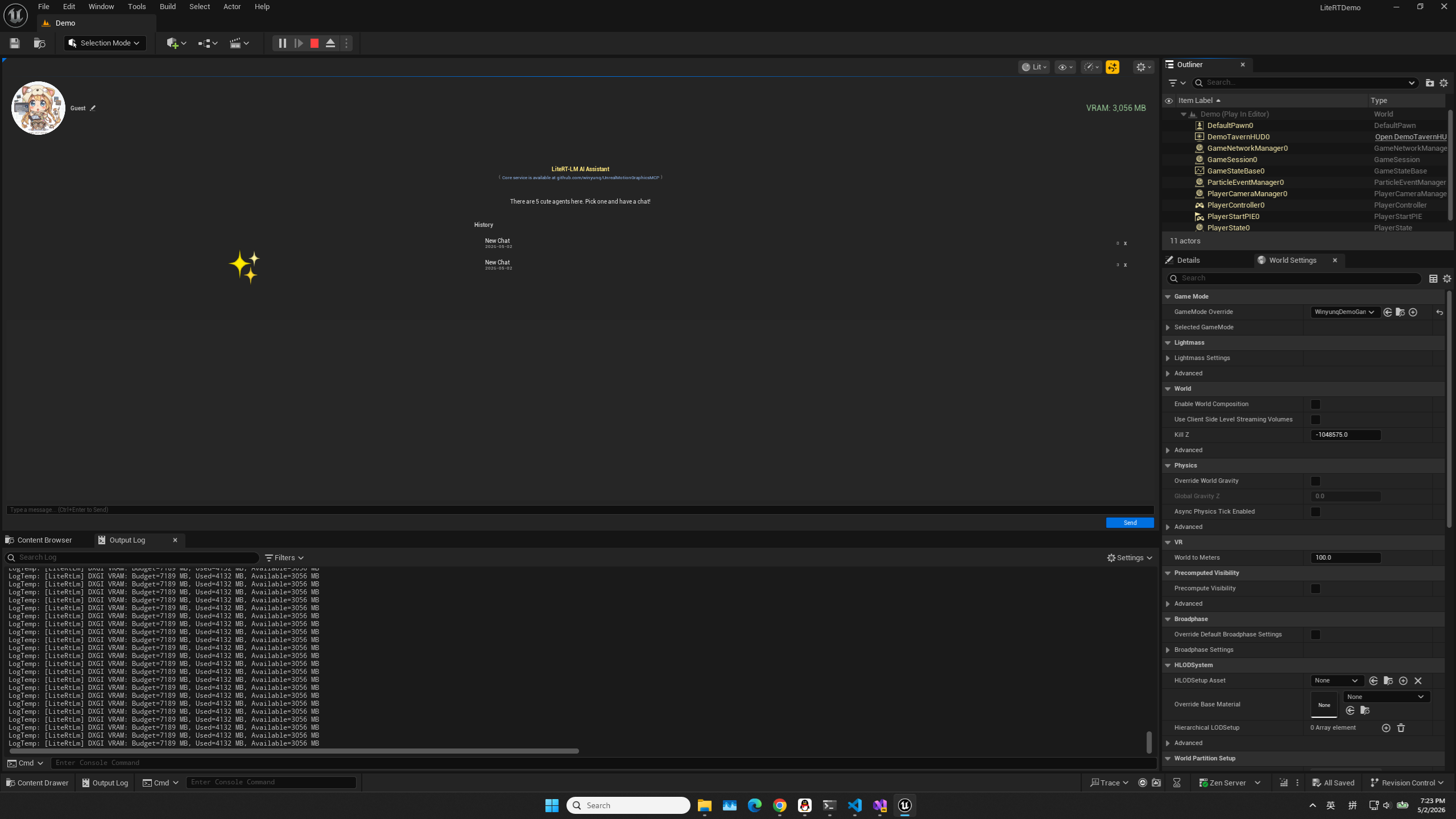
Real-time Text Interaction
Type a message in the dialogue box and press Enter. The plugin will automatically map your SessionKey to the KV Cache in VRAM.
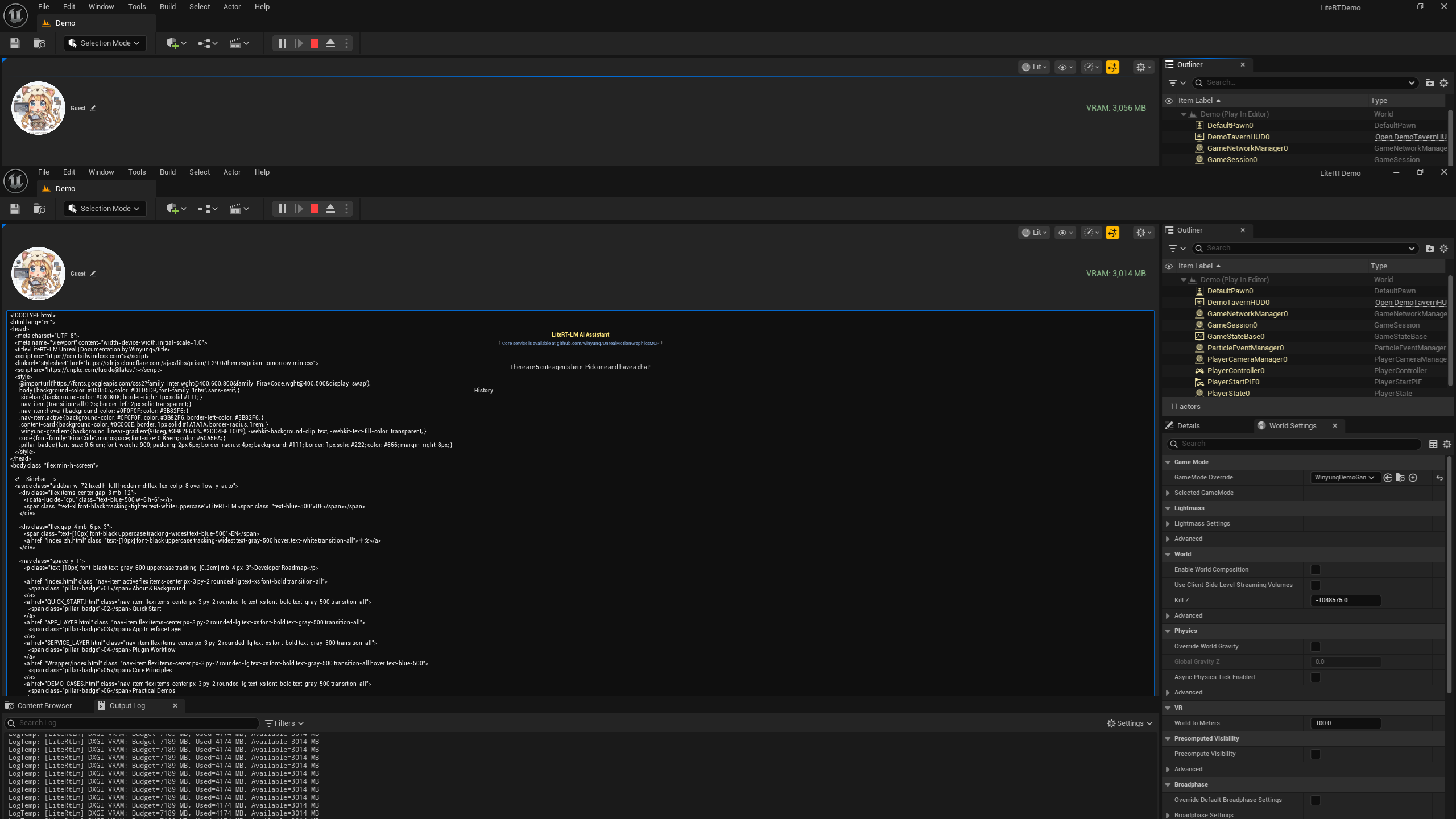
Streaming Responses & Memory
The AI will begin returning results word by word. Thanks to our multi-session management, NPCs will remember your conversation context, achieving true intelligent interaction.
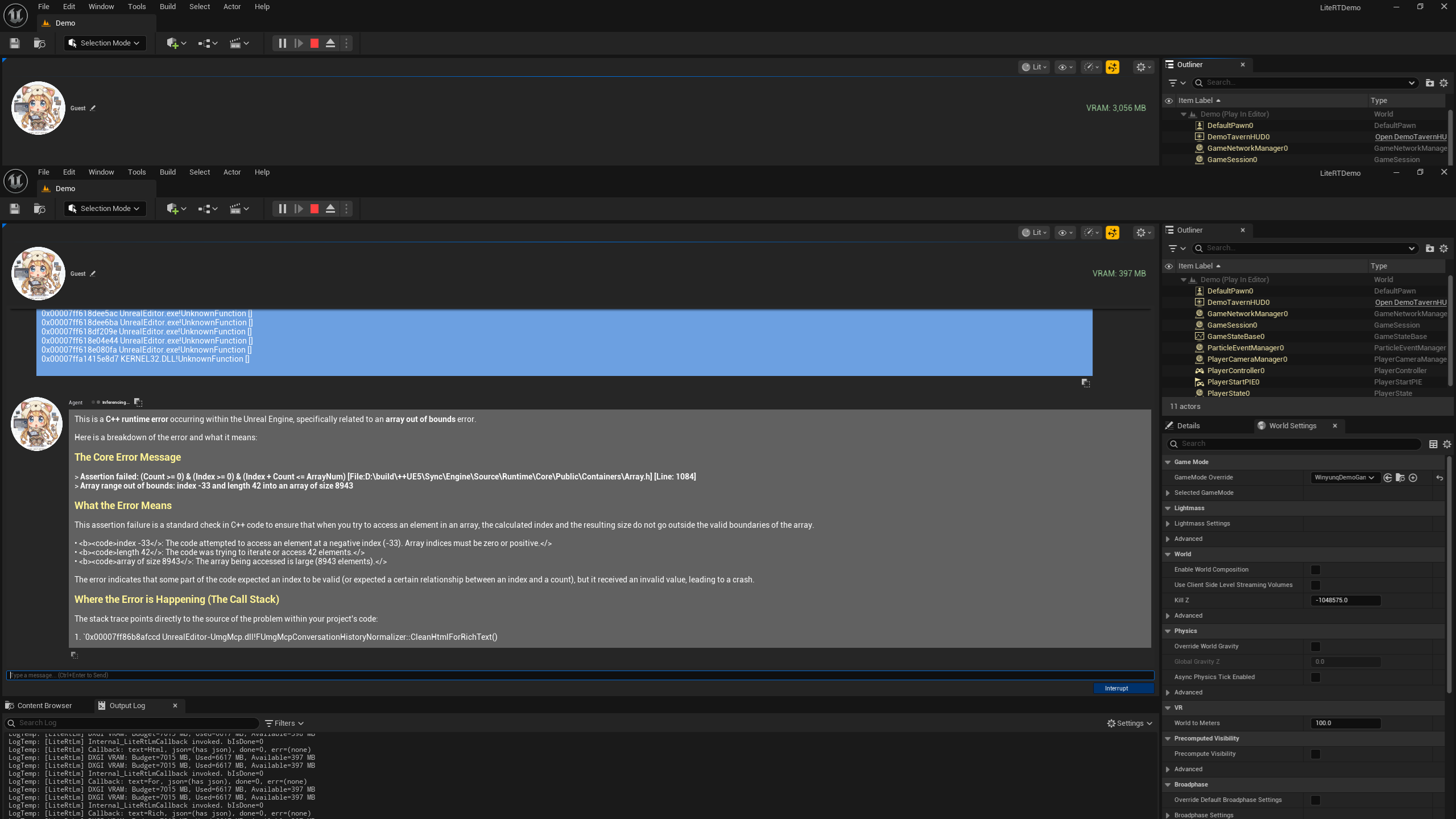
If you've successfully run the Demo, it's time to learn how to drive everything via C++.
Click me to Learning Coding